Introducción
En la investigación científica, el error de medición es la diferencia entre un valor observado y el valor real de algo. También se le llama error de observación o error experimental.
Hay dos tipos principales de error de medición:
- El error aleatorio es una diferencia aleatoria entre los valores observados y verdaderos de algo (p. ej., un investigador que lee mal una balanza registra una medición incorrecta).
- El error sistemático es una diferencia consistente o proporcional entre los valores observados y verdaderos de algo (p. ej., una báscula mal calibrada registra constantemente pesos más altos de lo que realmente son).
- Al reconocer las fuentes de error, puede reducir sus impactos y registrar mediciones exactas y precisas.
Desarrollo del tema
¿Son peores los errores aleatorios o sistemáticos?
En la investigación, los errores sistemáticos son generalmente un problema mayor que los errores aleatorios.
El error aleatorio no es necesariamente un error, sino una parte natural de la medición. Siempre hay cierta variabilidad en las mediciones, incluso cuando mide lo mismo repetidamente, debido a las fluctuaciones en el entorno, el instrumento o sus propias interpretaciones.
Pero la variabilidad puede ser un problema cuando afecta su capacidad para sacar conclusiones válidas sobre las relaciones entre variables. Esto es más probable que ocurra como resultado de un error sistemático.
Precisión vs exactitud
El error aleatorio afecta principalmente a la precisión, que es cuán reproducible es la misma medición en circunstancias equivalentes. Por el contrario, el error sistemático afecta la precisión de una medición, o qué tan cerca está el valor observado del valor real.
Tomar medidas es similar a golpear un objetivo central en un tablero de dardos. Para obtener mediciones precisas, su objetivo es llevar su dardo (sus observaciones) lo más cerca posible del objetivo (los valores reales). Para mediciones precisas, su objetivo es obtener observaciones repetidas lo más cerca posible entre sí.
El error aleatorio introduce variabilidad entre diferentes medidas de la misma cosa, mientras que el error sistemático sesga la medida del valor real en una dirección específica.
Cuando solo tiene un error aleatorio, si mide lo mismo varias veces, sus mediciones tenderán a agruparse o variar alrededor del valor real. Algunos valores serán más altos que la puntuación real, mientras que otros serán más bajos. Cuando promedies estas medidas, te acercarás mucho a la puntuación real.
Por esta razón, el error aleatorio no se considera un gran problema cuando recopila datos de una muestra grande; los errores en diferentes direcciones se cancelarán entre sí cuando calcule las estadísticas descriptivas. Pero podría afectar la precisión de su conjunto de datos cuando tiene una muestra pequeña.
Los errores sistemáticos son mucho más problemáticos que los errores aleatorios porque pueden sesgar sus datos para llevarlo a conclusiones falsas. Si tiene un error sistemático, sus mediciones se desviarán de los valores reales. En última instancia, puede llegar a una conclusión falsa positiva o falsa negativa (un error de tipo I o II) sobre la relación entre las variables que está estudiando.
Error al azar
El error aleatorio afecta sus medidas de manera impredecible: es igualmente probable que sus medidas sean más altas o más bajas que los valores reales.
En el siguiente gráfico, la línea negra representa una coincidencia perfecta entre las puntuaciones reales y las puntuaciones observadas de una escala. En un mundo ideal, todos sus datos caerían exactamente en esa línea. Los puntos verdes representan los puntajes reales observados para cada medición con el error aleatorio agregado.
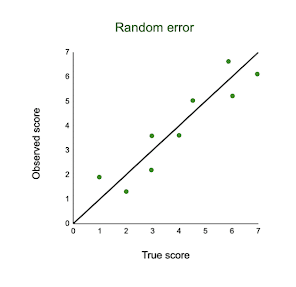
El error aleatorio se conoce como «ruido», porque borra el valor real (o la «señal») de lo que se mide. Mantener el error aleatorio bajo ayuda a recopilar datos precisos.
Fuentes de errores aleatorios
Algunas fuentes comunes de error aleatorio incluyen:
- variaciones naturales en el mundo real o contextos experimentales.
- instrumentos de medida imprecisos o poco fiables.
- diferencias individuales entre participantes o unidades.
- procedimientos experimentales mal controlados.
| Fuente de error aleatoria | Ejemplo |
|---|---|
| Variaciones naturales en contexto | En un experimento sobre la capacidad de la memoria, se programan pruebas de memoria a los participantes en diferentes momentos del día. Sin embargo, algunos participantes tienden a desempeñarse mejor por la mañana, mientras que otros lo hacen más tarde en el día, por lo que sus mediciones no reflejan el verdadero alcance de la capacidad de memoria de cada individuo. |
| Instrumento impreciso | La circunferencia de la muñeca se mide con una cinta métrica. Pero su cinta métrica sólo es precisa al medio centímetro más cercano, por lo que redondea cada medida hacia arriba o hacia abajo cuando registra datos. |
| Diferencias individuales | Pide a los participantes que se administren una descarga eléctrica segura y califiquen su nivel de dolor en una escala de calificación de 7 puntos. Debido a que el dolor es subjetivo, es difícil de medir de manera confiable. Algunos participantes exageran sus niveles de dolor, mientras que otros subestiman sus niveles de dolor. |
Reducir el error aleatorio
El error aleatorio casi siempre está presente en la investigación, incluso en entornos muy controlados. Si bien no puede erradicarlo por completo, puede reducir el error aleatorio utilizando los siguientes métodos.
Tomar medidas repetidas
Una forma sencilla de aumentar la precisión es tomando medidas repetidas y usando su promedio. Por ejemplo, puede medir la circunferencia de la muñeca de un participante tres veces y obtener longitudes ligeramente diferentes cada vez. Tomar la media de las tres medidas, en lugar de usar solo una, lo acerca mucho más al valor real.
Aumente el tamaño de su muestra
Las muestras grandes tienen menos errores aleatorios que las muestras pequeñas. Esto se debe a que los errores en diferentes direcciones se cancelan entre sí de manera más eficiente cuando tiene más puntos de datos. La recopilación de datos de una muestra grande aumenta la precisión y el poder estadístico.
Variables de control
En experimentos controlados, debe controlar cuidadosamente cualquier variable extraña que pueda afectar sus mediciones. Estos deben controlarse para todos los participantes para que elimine las fuentes clave de error aleatorio en todos los ámbitos.
Error sistemático
El error sistemático significa que sus medidas de la misma cosa variarán de manera predecible: cada medida diferirá de la medida real en la misma dirección, e incluso en la misma cantidad en algunos casos.
El error sistemático también se conoce como sesgo porque sus datos están sesgados en formas estandarizadas que ocultan los valores verdaderos. Esto puede conducir a conclusiones inexactas.
Tipos de errores sistemáticos
Los errores de compensación y los errores de factor de escala son dos tipos cuantificables de error sistemático.
Se produce un error de compensación cuando una báscula no está calibrada en un punto cero correcto. También se llama error aditivo o error de puesta a cero.

Ejemplo: error de compensación
Al medir las circunferencias de las muñecas de los participantes, interpretó mal el “2” en la cinta métrica como un punto cero. Todas sus medidas tienen 2 centímetros adicionales agregados.
Un error de factor de escala es cuando las mediciones difieren consistentemente del valor real proporcionalmente (por ejemplo, en un 10%). También se conoce como error sistemático correlacional o error multiplicador.

Ejemplo: error de factor de escala
Una balanza agrega consistentemente 10% a cada peso. Un peso real de 10 kg se registra como 11 kg, mientras que un peso real de 40 kg se registra como 44 kg.
Puede trazar errores de compensación y errores de factor de escala en gráficos para identificar sus diferencias. En los gráficos a continuación, la línea negra muestra cuándo su valor observado es el valor real exacto y no hay error aleatorio.
La línea azul es un error de compensación: desplaza todos los valores observados hacia arriba o hacia abajo en una cantidad fija (aquí, es una unidad adicional).
La línea rosa es un error de factor de escala: todos los valores observados se multiplican por un factor; todos los valores se desplazan en la misma dirección en la misma proporción, pero en diferentes cantidades absolutas.
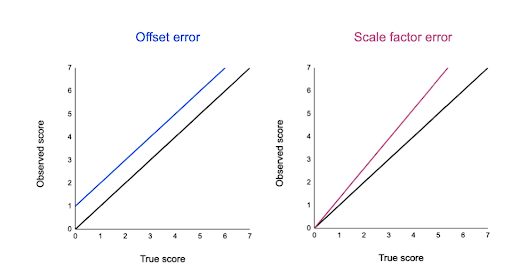
Fuentes de errores sistemáticos
Las fuentes de error sistemático pueden variar desde sus materiales de investigación hasta sus procedimientos de recopilación de datos y sus técnicas de análisis. Esta no es una lista exhaustiva de fuentes de errores sistemáticos, ya que pueden provenir de todos los aspectos de la investigación.
El sesgo de respuesta ocurre cuando sus materiales de investigación (p. ej., cuestionarios) incitan a los participantes a responder o actuar de manera no auténtica a través de preguntas capciosas. Por ejemplo, el sesgo de deseabilidad social puede hacer que los participantes traten de ajustarse a las normas sociales, incluso si no es así como realmente se sienten.
| Ejemplo: Pregunta principal En una encuesta, pides a los participantes su opinión sobre las acciones contra el cambio climático. Su pregunta dice: “Los expertos creen que solo las acciones sistemáticas pueden reducir los efectos del cambio climático. ¿Estás de acuerdo en que las acciones individuales no tienen sentido? Al citar «opiniones de expertos», este tipo de pregunta cargada indica a los participantes que deben estar de acuerdo con la opinión o correr el riesgo de parecer ignorantes. Los participantes pueden responder a regañadientes que están de acuerdo con la declaración, incluso cuando no es así. |
La deriva del experimentador ocurre cuando los observadores se fatigan, aburren o pierden motivación después de largos períodos de recopilación o codificación de datos, y se alejan lentamente del uso de procedimientos estandarizados de maneras identificables.
| Ejemplo: Deriva del experimentador (observador) Está codificando cualitativamente videos de experimentos sociales para observar cualquier acción o comportamiento cooperativo entre los participantes. Inicialmente, codifica todos los comportamientos sutiles y obvios que se ajustan a su criterio de cooperación. Pero después de pasar días en esta tarea, sólo codifica acciones extremadamente útiles como cooperativas. Gradualmente se aleja del criterio estándar original para codificar datos y sus mediciones se vuelven menos confiables. |
El sesgo de muestreo ocurre cuando es más probable que algunos miembros de una población se incluyan en su estudio que otros. Reduce la generalización de sus hallazgos, porque su muestra no es representativa de toda la población.
Reducción del error sistemático
Puede reducir los errores sistemáticos implementando estos métodos en su estudio.
Triangulación
La triangulación significa el uso de múltiples técnicas para registrar las observaciones, de modo que no dependa de un solo instrumento o método.
Por ejemplo, si está midiendo los niveles de estrés, puede usar las respuestas de la encuesta, los registros fisiológicos y los tiempos de reacción como indicadores. Puede verificar si estas tres medidas convergen o se superponen para asegurarse de que sus resultados no dependan del instrumento exacto utilizado.
Calibración regular
Calibrar un instrumento significa comparar lo que registra el instrumento con el valor real de una cantidad estándar conocida. Calibrar regularmente su instrumento con una referencia precisa ayuda a reducir la probabilidad de errores sistemáticos que afecten su estudio.
También puede calibrar a los observadores o investigadores en términos de cómo codifican o registran los datos. Use protocolos estándar y verificaciones de rutina para evitar la desviación del experimentador.
Aleatorización
Los métodos de muestreo aleatorio ayudan a garantizar que su muestra no difiera sistemáticamente de la población.
Además, si está realizando un experimento, utilice la asignación aleatoria para colocar a los participantes en diferentes condiciones de tratamiento. Esto ayuda a contrarrestar el sesgo al equilibrar las características de los participantes entre los grupos.
Enmascaramiento
Siempre que sea posible, debe ocultar la asignación de condiciones a los participantes e investigadores a través del enmascaramiento (cegamiento).
Los comportamientos o las respuestas de los participantes pueden verse influenciados por las expectativas del experimentador y las características de la demanda en el entorno, por lo que controlarlas ayudará a reducir el sesgo sistemático.
Preguntas frecuentes sobre error aleatorio y sistemático
¿Cuál es la diferencia entre error aleatorio y sistemático?
El error aleatorio y sistemático son dos tipos de error de medición.
El error aleatorio es una diferencia aleatoria entre los valores observados y verdaderos de algo (p. ej., un investigador que lee mal una balanza registra una medición incorrecta).
El error sistemático es una diferencia consistente o proporcional entre los valores observados y verdaderos de algo (p. ej., una báscula mal calibrada constantemente registra pesos más altos de lo que realmente son).
¿Es peor el error aleatorio o el error sistemático?
El error sistemático es generalmente un problema mayor en la investigación.
Con un error aleatorio, las mediciones múltiples tenderán a agruparse alrededor del valor real. Cuando recopila datos de una muestra grande, los errores en diferentes direcciones se cancelarán entre sí.
Los errores sistemáticos son mucho más problemáticos porque pueden distorsionar los datos del valor real. Esto puede llevar a conclusiones falsas ( errores de tipo I y II ) sobre la relación entre las variables que está estudiando.
¿Cómo evitar errores de medición?
El error aleatorio casi siempre está presente en los estudios científicos, incluso en entornos muy controlados. Si bien no puede erradicarlo por completo, puede reducir el error aleatorio tomando medidas repetidas, usando una muestra grande y controlando las variables extrañas.
Puede evitar errores sistemáticos mediante un diseño cuidadoso de sus procedimientos de muestreo, recopilación de datos y análisis. Por ejemplo, use la triangulación para medir sus variables usando múltiples métodos; calibrar regularmente instrumentos o procedimientos; utilizar muestreo aleatorio y asignación aleatoria; y aplicar enmascaramiento (cegamiento) donde sea posible.
Conclusión
Una vez abordado el tópico en cuestión, resulta relevante enfatizar que el error aleatorio varía de manera impredecible de una medición a otra, mientras que el error sistemático tiene el mismo valor o proporción para cada medición. Los errores aleatorios son inevitables, pero se agrupan alrededor del valor real. El error sistemático a menudo se puede evitar calibrando el equipo, pero si no se corrige, puede dar lugar a mediciones que distan mucho del valor real. De lo anterior podemos concluir que:
- Los dos tipos principales de error de medición son el error aleatorio y el error sistemático.
El error aleatorio hace que una medida difiera ligeramente de la siguiente. Proviene de cambios impredecibles durante un experimento. - El error sistemático siempre afecta las medidas en la misma cantidad o en la misma proporción, siempre que se tome una lectura de la misma manera cada vez es predecible.
- Los errores aleatorios no se pueden eliminar de un experimento, pero se pueden reducir la mayoría de los errores sistemáticos.
Fuentes consultadas
- Bhandari, P. (2021, mayo 7). Random vs. Systematic error. Scribbr. https://www.scribbr.com/methodology/random-vs-systematic-error/
- Helmenstine, A. M. (2018, septiembre 17). What’s the difference between random and systematic error? ThoughtCo. https://www.thoughtco.com/random-vs-systematic-error-4175358