Introducción
El análisis estadístico significa investigar tendencias, patrones y relaciones utilizando datos cuantitativos. Es una importante herramienta de investigación utilizada por científicos, gobiernos, empresas y otras organizaciones. Para sacar conclusiones válidas, el análisis estadístico requiere una planificación cuidadosa desde el comienzo mismo del proceso de investigación. Debe especificar sus hipótesis y tomar decisiones sobre el diseño de su investigación, el tamaño de la muestra y el procedimiento de muestreo.
Después de recolectar datos de su muestra, puede organizar y resumir los datos usando estadísticas descriptivas. Luego, puede usar estadísticas inferenciales para probar hipótesis formalmente y hacer estimaciones sobre la población. Finalmente, se puede interpretar y generalizar los hallazgos.
Este artículo es una introducción práctica al análisis estadístico, que te guiará a través de los pasos usando dos ejemplos de investigación. El primero investiga una posible relación de causa y efecto, mientras que el segundo investiga una posible correlación entre variables.
| Ejemplo: pregunta de investigación causal ¿Puede la meditación mejorar el rendimiento en los exámenes de los adolescentes? Ejemplo: pregunta de investigación correlacional ¿Existe una relación entre los ingresos de los padres y el promedio de calificaciones universitarias (GPA)? |
Desarrollo del tema
Paso 1: Escriba sus hipótesis y planifique su diseño de investigación
Para recopilar datos válidos para el análisis estadístico, primero se deben especificar las hipótesis y planificar el diseño de la investigación.
Escribir hipótesis estadísticas
El objetivo de la investigación es a menudo investigar una relación entre las variables dentro de una población. Comienza con una predicción y utiliza el análisis estadístico para probar esa predicción.
Una hipótesis estadística es una forma formal de escribir una predicción sobre una población. Cada predicción de investigación se reformula en hipótesis nulas y alternativas que se pueden probar utilizando datos de muestra.
Mientras que la hipótesis nula siempre predice ningún efecto o relación entre las variables, la hipótesis alternativa establece la predicción de la investigación de un efecto o relación.
| Ejemplo: Hipótesis estadísticas para probar un efecto – Hipótesis nula: un ejercicio de meditación de 5 minutos no tendrá ningún efecto en los puntajes de las pruebas de matemáticas en los adolescentes. – Hipótesis alternativa: un ejercicio de meditación de 5 minutos mejorará los puntajes de las pruebas de matemáticas en los adolescentes. Ejemplo: Hipótesis estadísticas para probar una correlación – Hipótesis nula: los ingresos de los padres y el GPA no tienen relación entre sí en los estudiantes universitarios. – Hipótesis alternativa: los ingresos de los padres y el GPA están correlacionados positivamente en los estudiantes universitarios. |
Planificación de su diseño de investigación
Un diseño de investigación es la estrategia general para la recopilación y el análisis de datos. Determinar las pruebas estadísticas que se puedan usar para probar la hipótesis más adelante.
Primero, decidir si la investigación utilizará un diseño descriptivo, correlacional o experimental. Los experimentos influyen directamente en las variables, mientras que los estudios descriptivos y correlacionales solo miden variables.
- En un diseño experimental, se puede evaluar una relación de causa y efecto (p. ej., el efecto de la meditación en los puntajes de las pruebas) mediante pruebas estadísticas de comparación o regresión.
- En un diseño correlacional, se puede explorar las relaciones entre las variables (p. ej., los ingresos de los padres y el GPA) sin ningún supuesto de causalidad utilizando coeficientes de correlación y pruebas de significación.
- En un diseño descriptivo, se puede estudiar las características de una población o un fenómeno (p. ej., la prevalencia de la ansiedad en estudiantes universitarios de EE. UU.) mediante pruebas estadísticas para extraer inferencias de datos de muestra.
El diseño de investigación también se refiere a si comparará a los participantes a nivel grupal o individual, o ambos.
- En un diseño entre sujetos, se comparan los resultados a nivel de grupo de los participantes que han estado expuestos a diferentes tratamientos (p. ej., los que realizaron un ejercicio de meditación frente a los que no lo hicieron).
- En un diseño dentro de los sujetos, se comparan medidas repetidas de participantes que han participado en todos los tratamientos de un estudio (p. ej., puntuaciones de antes y después de realizar un ejercicio de meditación).
- En un diseño mixto (factorial) , una variable se modifica entre los sujetos y otra se modifica dentro de los sujetos (p. ej., puntuaciones previas y posteriores a la prueba de los participantes que hicieron o no un ejercicio de meditación).
| Experimental | Correlacional |
|---|---|
| Ejemplo: diseño de investigación experimental Diseñas un experimento dentro de los sujetos para estudiar si un ejercicio de meditación de 5 minutos puede mejorar los puntajes de las pruebas de matemáticas. El estudio toma medidas repetidas de un grupo de participantes. Primero, tomarás los puntajes de las pruebas de referencia de los participantes. Luego, los participantes se someterán a un ejercicio de meditación de 5 minutos. Finalmente, registrará las puntuaciones de los participantes en una segunda prueba de matemáticas. En este experimento, la variable independiente es el ejercicio de meditación de 5 minutos y la variable dependiente es el puntaje del examen de matemáticas antes y después de la intervención. | Ejemplo: diseño de investigación correlacional En un estudio correlacional, se prueba si existe una relación entre los ingresos de los padres y el GPA de los estudiantes universitarios que se gradúan. Para recopilar los datos, se pedirá a los participantes que completen una encuesta y que informen ellos mismos los ingresos de sus padres y su propio GPA. No hay variables dependientes o independientes en este estudio, porque solo desea medir variables sin influir en ellas de ninguna manera. |
Variables de medición
Al planificar un diseño de investigación, debe operacionalizar sus variables y decidir exactamente cómo las medirá. Para el análisis estadístico, es importante considerar el nivel de medición de sus variables, que le indica qué tipo de datos contienen:
- Los datos categóricos representan agrupaciones. Estos pueden ser nominales (p. ej., género) u ordinales (p. ej., nivel de habilidad lingüística).
- Los datos cuantitativos representan cantidades. Estos pueden estar en una escala de intervalo (p. ej., la puntuación de un examen) o una escala de razón (p. ej., la edad).
Muchas variables se pueden medir con diferentes niveles de precisión. Por ejemplo, los datos de edad pueden ser cuantitativos (8 años) o categóricos (jóvenes). Si una variable se codifica numéricamente (p. ej., nivel de acuerdo de 1 a 5), ??no significa automáticamente que sea cuantitativa en lugar de categórica.
Identificar el nivel de medición es importante para elegir las estadísticas y las pruebas de hipótesis apropiadas. Por ejemplo, puede calcular una puntuación media con datos cuantitativos, pero no con datos categóricos.
En un estudio de investigación, junto con las medidas de las variables de interés, a menudo se recopilarán datos sobre las características relevantes de los participantes.
Experimental
Ejemplo: Variable (Experimento)
Se pueden realizar muchos cálculos con datos cuantitativos de edad o puntaje de prueba, mientras que las variables categóricas se pueden usar para decidir agrupaciones para pruebas de comparación.
| Variable | Tipo de datos |
|---|---|
| Años | Cuantitativo (razón) |
| Género | Categórico (nominal) |
| Raza o etnia | Categórico (nominal) |
| Puntuaciones de las pruebas de referencia | Cuantitativo (intervalo) |
| Puntajes de las pruebas finales | Cuantitativo (intervalo) |
Correlacional
Ejemplo: Variables (estudio correlacional)
Los tipos de variables en un estudio correlacional determinan la prueba que utilizarás para un coeficiente de correlación. Se puede usar una prueba de correlación paramétrica para datos cuantitativos, mientras que se debe usar una prueba de correlación no paramétrica si una de las variables es ordinal.
| Variable | Tipo de datos |
|---|---|
| Ingresos de los padres | Cuantitativo (razón) |
| GPA | Cuantitativo (intervalo) |
Paso 2: recopilar datos de una muestra
En la mayoría de los casos, es demasiado difícil o costoso recopilar datos de cada miembro de la población que le interesa estudiar. En su lugar, recopilará datos de una muestra.
El análisis estadístico le permite aplicar sus hallazgos más allá de la propia muestra, siempre que se utilicen los procedimientos de muestreo adecuados. Se debe apuntar a una muestra que sea representativa de la población.
Muestreo para análisis estadístico
Hay dos enfoques principales para seleccionar una muestra.
- Muestreo probabilístico: cada miembro de la población tiene la posibilidad de ser seleccionado para el estudio a través de una selección aleatoria.
- Muestreo no probabilístico: algunos miembros de la población tienen más probabilidades que otros de ser seleccionados para el estudio debido a criterios como la conveniencia o la autoselección voluntaria.
En teoría, para hallazgos altamente generalizables, se debe usar un método de muestreo probabilístico. La selección aleatoria reduce el sesgo de muestreo y garantiza que los datos de su muestra sean realmente típicos de la población. Las pruebas paramétricas se pueden usar para hacer inferencias estadísticas sólidas cuando los datos se recopilan mediante muestreo probabilístico.
Pero en la práctica, rara vez es posible reunir la muestra ideal. Si bien es más probable que las muestras no probabilísticas estén sesgadas, son mucho más fáciles de reclutar y recopilar datos. Las pruebas no paramétricas son más apropiadas para muestras no probabilísticas, pero generan inferencias más débiles sobre la población.
Si se desea utilizar pruebas paramétricas para muestras no probabilísticas, debe demostrar que:
- La muestra es representativa de la población a la que está generalizando sus hallazgos.
- La muestra carece de sesgo sistemático.
Tenga en cuenta que la validez externa significa que solo puede generalizar sus conclusiones a otras personas que comparten las características de su muestra. Por ejemplo, los resultados de muestras occidentales, educadas, industrializadas, ricas y demócratas (por ejemplo, estudiantes universitarios en los EE. UU.) no se aplican automáticamente a todas las poblaciones que no son WEIRD.
Si se aplican pruebas paramétricas a datos de muestras no probabilísticas, se debe asegurar de explicar las limitaciones de hasta qué punto se pueden generalizar los resultados en la sección de discusión.
Crear un procedimiento de muestreo apropiado
Según los recursos disponibles para la investigación, decide cómo reclutarás participantes.
- ¿Tendrás recursos para publicitar ampliamente el estudio, incluso fuera del entorno universitario?
- ¿Tendrás los medios para reclutar una muestra diversa que represente a una población amplia?
- ¿Tienes tiempo para ponerte en contacto y hacer un seguimiento de los miembros de los grupos de difícil acceso?
Experimental
Ejemplo: Muestreo (experimento)
La población que te interesa son los estudiantes de secundaria de tu ciudad. Te pones en contacto con tres escuelas privadas y siete escuelas públicas en varios distritos de la ciudad para ver si puedes administrar el experimento a estudiantes en el grado 11.
Los participantes son autoseleccionados por escuelas. Aunque se esta utilizando una muestra no probabilística, el objetivo es una muestra diversa y representativa.
Correlacional
Ejemplo: Muestreo (estudio correlacional)
Su principal población de interés son los estudiantes universitarios varones de EE. UU. Mediante la publicidad en las redes sociales, recluta a estudiantes universitarios masculinos de último año de una subpoblación más pequeña: siete universidades en el área de Bostón.
Sus participantes se ofrecen como voluntarios para la encuesta, por lo que esta es una muestra no probabilística.
Calcular tamaño de muestra suficiente
Antes de reclutar participantes, decida el tamaño de su muestra, ya sea mirando otros estudios en su campo o usando estadísticas. Una muestra demasiado pequeña puede no ser representativa de la muestra, mientras que una muestra demasiado grande será más costosa de lo necesario.
Hay muchas calculadoras de tamaño de muestra en línea. Se utilizan diferentes fórmulas dependiendo de si tiene subgrupos o cuán riguroso debe ser su estudio (p. ej., en investigación clínica). Como regla general, se necesita un mínimo de 30 unidades o más por subgrupo.
Para usar estas calculadoras, debe comprender e ingresar estos componentes clave:
- Nivel de significación (alfa): el riesgo de rechazar una hipótesis nula verdadera que se está dispuesto a asumir, normalmente fijado en un 5 %.
- Poder estadístico: la probabilidad de que su estudio detecte un efecto de cierto tamaño, si lo hay, generalmente del 80% o más.
- Tamaño del efecto esperado: una indicación estandarizada de qué tan grande será el resultado esperado del estudio, generalmente basado en otros estudios similares.
- Desviación estándar de la población: una estimación del parámetro de la población basada en un estudio anterior o en un estudio piloto propio.
Paso 3: Resume los datos con estadísticas descriptivas
Una vez que haya recopilado todos sus datos, puede inspeccionarlos y calcular estadísticas descriptivas que los resuman.
Inspeccione sus datos
Hay varias formas de inspeccionar sus datos, incluidas las siguientes:
- Organizar los datos de cada variable en tablas de distribución de frecuencias.
- Mostrar datos de una variable clave en un gráfico de barras para ver la distribución de las respuestas.
- Visualización de la relación entre dos variables mediante un diagrama de dispersión.
Al visualizar los datos en tablas y gráficos, se puede evaluar si los datos siguen una distribución sesgada o normal y si hay valores atípicos o datos faltantes.
Una distribución normal significa que los datos se distribuyen simétricamente alrededor de un centro donde se encuentran la mayoría de los valores, con los valores disminuyendo en los extremos de la cola.
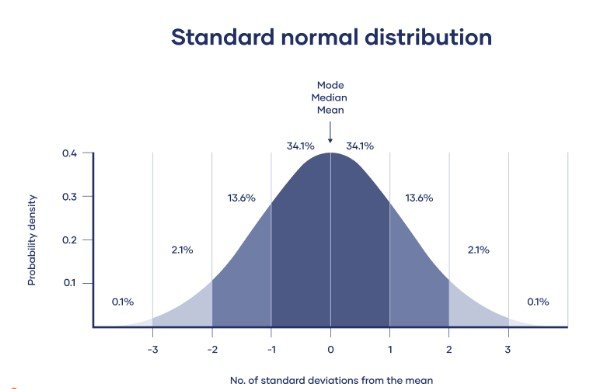
Por el contrario, una distribución sesgada es asimétrica y tiene más valores en un extremo que en el otro. Es importante tener en cuenta la forma de la distribución porque solo se deben usar algunas estadísticas descriptivas con distribuciones asimétricas.
Los valores atípicos extremos también pueden producir estadísticas engañosas, por lo que es posible que necesite un enfoque sistemático para manejar estos valores.
Calcular medidas de tendencia central
Las medidas de tendencia central describen dónde se encuentran la mayoría de los valores en un conjunto de datos. A menudo se informan tres medidas principales de tendencia central:
- Moda: la respuesta o valor más popular en el conjunto de datos.
- Mediana: el valor en el medio exacto del conjunto de datos cuando se ordena de menor a mayor.
- Media: la suma de todos los valores dividida por el número de valores.
Sin embargo, según la forma de la distribución y el nivel de medición, solo una o dos de estas medidas pueden ser apropiadas. Por ejemplo, muchas características demográficas solo se pueden describir mediante la moda o las proporciones, mientras que una variable como el tiempo de reacción puede no tener moda alguna.
Calcular medidas de variabilidad
Las medidas de variabilidad le indican qué tan dispersos están los valores en un conjunto de datos. A menudo se informan cuatro medidas principales de variabilidad:
- Rango: el valor más alto menos el valor más bajo del conjunto de datos.
- Rango intercuartílico: el rango de la mitad central del conjunto de datos.
- Desviación estándar: la distancia promedio entre cada valor en el conjunto de datos y la media.
- Varianza: el cuadrado de la desviación estándar.
Una vez más, la forma de la distribución y el nivel de medición deben guiar la elección de estadísticas de variabilidad. El rango intercuartílico es la mejor medida para las distribuciones asimétricas, mientras que la desviación estándar y la varianza brindan la mejor información para las distribuciones normales.
Experimental
Ejemplo: Estadísticas descriptivas (experimento)
Después de recopilar datos previos y posteriores a la prueba de 30 estudiantes de toda la ciudad, calcula estadísticas descriptivas. Debido a que tiene datos distribuidos normalmente en una escala de intervalo, tabula la media, la desviación estándar, la varianza y el rango.
Usando la tabla, se debe verificar si las unidades de las estadísticas descriptivas son comparables para las puntuaciones previas y posteriores a la prueba. Por ejemplo, ¿los niveles de varianza son similares entre los grupos? ¿Existen valores extremos? Si los hay, es posible que debas identificar y eliminar valores atípicos extremos en el conjunto de datos o transformar los datos antes de realizar una prueba estadística.
| Puntuaciones previas a la prueba | Puntuaciones posteriores a la prueba | |
|---|---|---|
| Significar | 68.44 | 75.25 |
| Desviación estándar | 9.43 | 9.88 |
| Diferencia | 88.96 | 97.96 |
| Rango | 36.25 | 45.12 |
| norte | 30 |
En esta tabla, podemos ver que la puntuación media aumentó después del ejercicio de meditación y las variaciones de las dos puntuaciones son comparables. A continuación, se puede realizar una prueba estadística para averiguar si esta mejora en los puntajes de las pruebas es estadísticamente significativa en la población.
Correlacional
Ejemplo: Estadística descriptiva (estudio correlacional)
Después de recopilar datos de 653 estudiantes, tabula estadísticas descriptivas para el ingreso anual de los padres y el GPA.
Es importante verificar si tienes una amplia gama de puntos de datos. Si no lo haces, tus datos pueden estar sesgados hacia algunos grupos más que otros (p. ej., estudiantes alto rendimiento académico), y sólo se pueden hacer inferencias limitadas sobre una relación.
| Ingresos de los padres (USD) | GPA | |
|---|---|---|
| Significar | 62,100 | 3.12 |
| Desviación estándar | 15,000 | 0,45 |
| Diferencia | 225,000,000 | 0.16 |
| Rango | 8,000-378,000 | 2.64-4.00 |
| norte | 653 |
A continuación, podemos calcular un coeficiente de correlación y realizar una prueba estadística para comprender la importancia de la relación entre las variables de la población.
Paso 4: Pruebe hipótesis o haga estimaciones con estadística inferencial
Un número que describe una muestra se llama estadística , mientras que un número que describe una población se llama parámetro. Con las estadísticas inferenciales, puede sacar conclusiones sobre los parámetros de la población en función de las estadísticas de muestra.
Los investigadores a menudo usan dos métodos principales (simultáneamente) para hacer inferencias en estadística.
Estimación: cálculo de parámetros poblacionales a partir de estadísticos muestrales.
Prueba de hipótesis: un proceso formal para probar las predicciones de la investigación sobre la población usando muestras.
Estimación
Puede hacer dos tipos de estimaciones de parámetros de población a partir de estadísticas de muestra:
- Una estimación puntual: un valor que representa su mejor estimación del parámetro exacto.
- Una estimación de intervalo: un rango de valores que representan su mejor estimación de dónde se encuentra el parámetro.
Si su objetivo es inferir y reportar las características de la población a partir de datos de muestra, es mejor usar estimaciones puntuales y de intervalo en su artículo.
Puede considerar una estadística de muestra como una estimación puntual para el parámetro de población cuando tiene una muestra representativa (p. ej., en una amplia encuesta de opinión pública, la proporción de una muestra que apoya al gobierno actual se toma como la proporción de la población de simpatizantes del gobierno).
Siempre hay un error involucrado en la estimación, por lo que también debe proporcionar un intervalo de confianza como una estimación de intervalo para mostrar la variabilidad en torno a una estimación puntual.
Un intervalo de confianza utiliza el error estándar y la puntuación z de la distribución normal estándar para indicar dónde esperaría encontrar el parámetro de población la mayor parte del tiempo.
Prueba de hipótesis
Con los datos de una muestra, puede probar hipótesis sobre las relaciones entre las variables de la población. La prueba de hipótesis comienza con la suposición de que la hipótesis nula es cierta en la población y utiliza pruebas estadísticas para evaluar si la hipótesis nula se puede rechazar o no.
Las pruebas estadísticas determinan dónde estarían sus datos de muestra en una distribución esperada de datos de muestra si la hipótesis nula fuera cierta. Estas pruebas dan dos resultados principales:
- Una estadística de prueba le dice cuánto difieren sus datos de la hipótesis nula de la prueba.
- Un valor p le indica la probabilidad de obtener sus resultados si la hipótesis nula es realmente cierta en la población.
- Las pruebas estadísticas vienen en tres variedades principales:
- Las pruebas de comparación evalúan las diferencias de grupo en los resultados.
- Las pruebas de regresión evalúan las relaciones de causa y efecto entre las variables.
- Las pruebas de correlación evalúan las relaciones entre las variables sin asumir causalidad.
Su elección de prueba estadística depende de sus preguntas de investigación, diseño de investigación, método de muestreo y características de los datos.
Pruebas paramétricas
Las pruebas paramétricas hacen poderosas inferencias sobre la población basadas en datos de muestra. Pero para usarlos, se deben cumplir algunos supuestos, y solo se pueden usar algunos tipos de variables. Si sus datos infringen estas suposiciones, puede realizar las transformaciones de datos adecuadas o utilizar pruebas no paramétricas alternativas en su lugar.
Una regresión modela la medida en que los cambios en una variable predictora dan como resultado cambios en la(s) variable(s) de resultado.
- Una regresión lineal simple incluye una variable predictora y una variable de resultado.
- Una regresión lineal múltiple incluye dos o más variables predictoras y una variable de resultado.
Las pruebas de comparación generalmente comparan las medias de los grupos. Estas pueden ser las medias de diferentes grupos dentro de una muestra (p. ej., un grupo de tratamiento y de control), las medias de un grupo de muestra tomado en diferentes momentos (p. ej., puntajes previos y posteriores a la prueba), o una media muestral y una media poblacional.
- Una prueba t es para exactamente 1 o 2 grupos cuando la muestra es pequeña (30 o menos).
- Una prueba z es para exactamente 1 o 2 grupos cuando la muestra es grande.
- Un ANOVA es para 3 o más grupos.
Las pruebas z y t tienen subtipos basados ??en el número y tipos de muestras y las hipótesis:
- Si solo se tiene una muestra que desea comparar con la media de una población, usa una prueba de una muestra.
- Si tiene mediciones pareadas (diseño dentro de los sujetos), use una prueba de muestras dependientes (pareadas).
- Si se tienen mediciones completamente separadas de dos grupos no emparejados (diseño entre sujetos), usa una prueba de muestras independientes (no apareadas) .
- Si se espera una diferencia entre los grupos en una dirección específica, usa una prueba de una cola.
Si no tienes ninguna expectativa sobre la dirección de una diferencia entre grupos, use una prueba de dos colas.
La única prueba de correlación paramétrica es la r de Pearson . El coeficiente de correlación ( r ) indica la fuerza de una relación lineal entre dos variables cuantitativas.
Sin embargo, para probar si la correlación en la muestra es lo suficientemente fuerte como para ser importante en la población, también debe realizar una prueba de significación del coeficiente de correlación, generalmente una prueba t , para obtener un valor p . Esta prueba utiliza el tamaño de su muestra para calcular cuánto difiere el coeficiente de correlación de cero en la población.
Experimental
Ejemplo: prueba t pareada para investigación experimental
Debido a que el diseño de tu investigación es un experimento dentro de los sujetos, las mediciones previas y posteriores a la prueba provienen del mismo grupo, por lo que necesitas una prueba t dependiente (pareada). Dado que predice un cambio en una dirección específica (una mejora en los puntajes de las pruebas), necesita una prueba de una cola.
Utilzar una prueba t de muestras dependientes de una cola para evaluar si el ejercicio de meditación mejoró significativamente los puntajes de las pruebas de matemáticas.
La prueba da:
- Un valor t (estadística de prueba) de 3,00
- Un valor p de 0.0028
Experimental
Ejemplo: Coeficiente de correlación y prueba de significancia
Utiliza la r de Pearson para calcular la fuerza de la relación lineal entre los ingresos de los padres y el GPA en su muestra. El valor r de Pearson es 0,12, lo que indica una pequeña correlación en la muestra.
Aunque la r de Pearson es una estadística de prueba, no dice nada sobre cuán significativa es la correlación en la población. También debe probar si este coeficiente de correlación de muestra es lo suficientemente grande como para demostrar una correlación en la población.
Una prueba t también puede determinar cuán significativamente un coeficiente de correlación difiere de cero en función del tamaño de la muestra. Dado que espera una correlación positiva entre los ingresos de los padres y el GPA, utiliza una prueba t de una muestra y una cola. La prueba t da:
- In valor t de 3.08
- un valor de p de 0.001
Paso 5: Interpreta tus resultados
El paso final del análisis estadístico es interpretar sus resultados.
Significancia estadística
En la prueba de hipótesis, la significancia estadística es el criterio principal para formar conclusiones. Compara su valor p con un nivel de significación establecido (generalmente 0,05) para decidir si los resultados son estadísticamente significativos o no significativos.
Se considera improbable que los resultados estadísticamente significativos hayan surgido únicamente debido al azar. Solo hay una probabilidad muy baja de que ocurra tal resultado si la hipótesis nula es cierta en la población.
| Experimental | Correlacional |
|---|---|
| Ejemplo: Interpreta tus resultados (experimento) Compara el valor p de 0,0027 con el umbral de significancia de 0,05. Como el valor p es más bajo, decide rechazar la hipótesis nula y considera que sus resultados son estadísticamente significativos. Esto significa que crees que la intervención de meditación, en lugar de factores aleatorios, causó directamente el aumento en los puntajes de las pruebas. | Ejemplo: Interprete sus resultados (estudio correlacional) Compara la valor p de 0,001 con el umbral de significación de 0,05. Con un valor de p por debajo de este umbral, puede rechazar la hipótesis nula. Esto indica una correlación estadísticamente significativa entre los ingresos de los padres y el GPA en los estudiantes universitarios varones. Ten en cuenta que la correlación no siempre significa causalidad, porque a menudo hay muchos factores subyacentes que contribuyen a una variable compleja como el GPA. Incluso si una variable está relacionada con otra, esto puede deberse a que una tercera variable influye en ambas, o a vínculos indirectos entre las dos variables. Un tamaño de muestra grande también puede influir fuertemente en la significación estadística de un coeficiente de correlación al hacer que los coeficientes de correlación muy pequeños parezcan significativos. |
Tamaño del efecto
Un resultado estadísticamente significativo no significa necesariamente que haya aplicaciones importantes en la vida real o resultados clínicos para un hallazgo.
Por el contrario, el tamaño del efecto indica la importancia práctica de sus resultados. Es importante informar los tamaños del efecto junto con sus estadísticas inferenciales para obtener una imagen completa de sus resultados. También debes informar las estimaciones de intervalo de los tamaños del efecto si está escribiendo un documento de estilo APA.
| Experimental | Correlacional |
|---|---|
| Ejemplo: tamaño del efecto (experimento) Calcular la d de Cohen para encontrar el tamaño de la diferencia entre las puntuaciones de la prueba previa y posterior. Con una d de Cohen de 0,72, el hallazgo de que el ejercicio de meditación mejoró los puntajes de las pruebas tiene una importancia práctica de media a alta. | Ejemplo: Tamaño del efecto (estudio correlacional) Para determinar el tamaño del efecto del coeficiente de correlación, compare el valor r de Pearson con el criterio del tamaño del efecto de Cohen. Debido a que el valor está entre 0,1 y 0,3, el hallazgo de una relación entre los ingresos de los padres y el GPA representa un efecto muy pequeño y tiene una importancia práctica limitada. |
Errores de decisión
Los errores tipo I y tipo II son errores cometidos en las conclusiones de la investigación. Un error de Tipo I significa rechazar la hipótesis nula cuando en realidad es verdadera, mientras que un error de Tipo II significa no rechazar la hipótesis nula cuando es falsa.
Puedes apuntar a minimizar el riesgo de estos errores seleccionando un nivel de significancia óptimo y asegurando un alto poder. Sin embargo, hay una compensación entre los dos errores, por lo que es necesario un buen equilibrio.
Estadística frecuentista versus bayesiana
Tradicionalmente, las estadísticas frecuentistas enfatizan las pruebas de significación de hipótesis nulas y siempre comienzan con la suposición de una hipótesis nula verdadera.
Sin embargo, las estadísticas bayesianas han ganado popularidad como enfoque alternativo en las últimas décadas. En este enfoque, utiliza investigaciones previas para actualizar continuamente sus hipótesis en función de sus expectativas y observaciones.
El factor de Bayes compara la fuerza relativa de la evidencia para la hipótesis nula frente a la alternativa en lugar de llegar a una conclusión sobre el rechazo o no de la hipótesis nula.
Conclusión
Es importante tener presente que el análisis estadístico, es el proceso de recopilar y analizar datos para discernir patrones y tendencias. Es un método para eliminar el sesgo de la evaluación de datos mediante el empleo de análisis numéricos. Esta técnica es útil para recopilar las interpretaciones de la investigación, desarrollar modelos estadísticos y planificar encuestas y estudios.
El análisis estadístico es una herramienta científica que ayuda a recopilar y analizar grandes cantidades de datos para identificar patrones y tendencias comunes para convertirlos en información significativa. En palabras simples, el análisis estadístico es una herramienta de análisis de datos que ayuda a sacar conclusiones significativas a partir de datos en bruto y no estructurados.
Fuentes consultadas
- Account details. (s/f). Statistics archieven. Scribbr. Recuperado el 30 de agosto de 2022, de https://www.scribbr.com/category/statistics/
- Simplilearn. (2021, November 16). What is Statistical Analysis? Types, Methods and Examples. Simplilearn.com; Simplilearn. https://www.simplilearn.com/what-is-statistical-analysis-article